
안녕하세요! 오늘은 원신 나무위키에 플레이어블 캐릭터와 성유물 카테고리의 글을 크롤링하는 코드에 대해 포스팅 진행하겠습니다.
해당 포스팅에서는 전체 코드와 결과물 이미지만 첨부합니다.
크롤링의 자세한 과정은 추후에 포스팅 진행하도록 하겠습니다.
해당 크롤링은 원신 각 캐릭터의 성유물 추천 옵션과 세트를 빠르게 파악하기 위한 데이터 수집을 목적으로 하고 있습니다!
나무위키에서 수집할 정보는 아래와 같습니다.
※ 사진 속 정보는 나히다를 예시로 한 것입니다.
1. 캐릭터의 이름, 속성, 무기
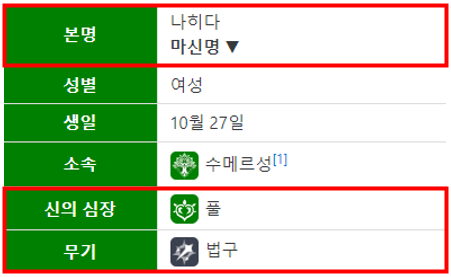
2. 권장 성유물 옵션

3. 추천 성유물 세트 및 설명

4. 성유물 이름, 세트 효과, 획득처

- 크롤링 진행 방식
크롤링은 총 3개의 코드로 진행을 합니다.
- 첫 번째 코드
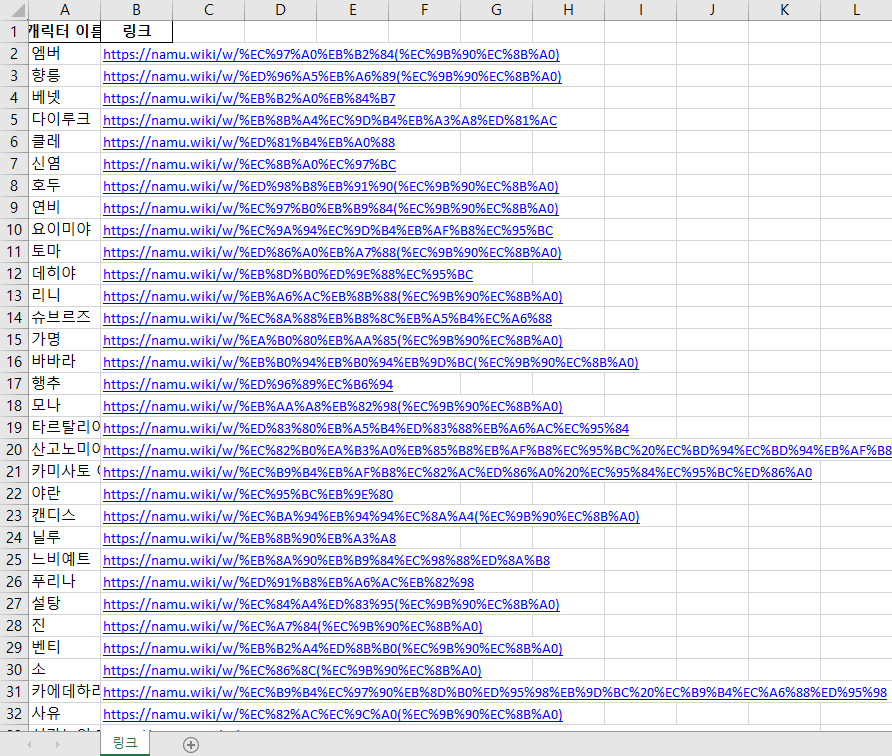
- 원신 캐릭터의 상세 정보가 담긴 링크를 전부 긁어옵니다.
- 캐릭터의 이름과 링크만 저장하여 하나의 엑셀 파일로 저장합니다.
- 두 번째 코드
- 첫 번째 코드에서 저장한 엑셀 파일에서 각 캐릭터의 상세 정보 링크를 가져옵니다.
- 캐릭터의 속성, 무기, 권장 성유물 옵션, 추천 성유물 세트 및 상세 설명의 내용을 가지고 옵니다.
- 캐릭터의 이름, 속성, 무기 권장 성유물 옵션을 저장하여 하나의 엑셀 파일로 저장합니다.
- 캐릭터의 이름, 추천 성유물 세트, 상세 설명을 저장하여 하나의 엑셀 파일로 저장합니다.
엑셀 파일을 두 개로 나눈 이유는 이후에 원신 캐릭터 성유물을 조회하는 엑셀 파일을 쉽게 만들기 위해서 입니다!
- 세번째 코드
- 성유물 세트 이름, 2세트, 4세트, 획득처의 내용을 가지고 옵니다.
- 획득처에서 비경의 이름을 분리합니다.
- 성유물 세트 이름, 2세트, 4세트, 획득처, 비경의 이름을 저장하여 하나의 엑셀 파일로 저장합니다.
비경 이름을 분리한 이유는 이후 원신 캐릭터 성유물을 조회하는 엑셀 파일을 쉽게 만들기 위해서 입니다!
[실제 코드 및 결과물]
- 첫 번째 코드
import pandas as pd
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as E
from openpyxl import *
# 원신/캐릭터 나무위키 링크
link = 'https://namu.wiki/w/%EC%9B%90%EC%8B%A0/%EC%BA%90%EB%A6%AD%ED%84%B0'
# 나무위키는 BeautifulSoup이 먹히지 않기 때문에 동적 크롤링으로 진행
driver = webdriver.Chrome('chromedriver.exe')
driver.get(link)
time.sleep(3)
# '원소별' 버튼 클릭
button = list(driver.find_elements(By.CLASS_NAME, "_3xTXXXtF"))
button[1].click()
time.sleep(3)
Character = pd.DataFrame({'캐릭터 이름' : [], '링크' : []})
character_info = driver.find_elements(By.CLASS_NAME, "s3zppxXT")
for i in range(len(character_info)) :
character = character_info[i]
# 캐릭터 이름만 담기 위해서 데이터를 정제하는 부분
# 캐릭터의 소개가 끝나는 부분
if character.text == '취소선' :
break
# 주인공 캐릭터인 아이테르와 루미네는 데이터 수집에서 제외
# 캐릭터 이름이 아닌데, 들어온 정보는 모두 제외
if character.text == '' or '원신' in character.text or '아이테르' in character.text or character.text in ['불', '물', '바람', '번개', '풀', '얼음', '바위'] :
pass
else :
# 캐릭터의 이름
name = character.text
# 캐릭터의 이름이 길 경우, 엔터로 구분이 되어있기 때문에 이를 띄어쓰기로 변경
if '\n' in name :
name = name.replace('\n', ' ')
Char = [name, str(character.get_attribute('href'))]
Character.loc[i] = Char
with pd.ExcelWriter('genshin_link.xlsx') as writer :
Character.to_excel(writer, sheet_name='링크', index=False)
- 첫 번째 코드 결과물
- 두 번째 코드
import pandas as pd
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as E
from openpyxl import *
# 캐릭터의 이름과 상세정보 링크가 담긴 엑셀 파일
link = pd.read_excel('genshin_link.xlsx')
Main_link = list(link['링크'])
Character = list(link['캐릭터 이름'])
Information = pd.DataFrame({'캐릭터 이름' : [], '무기' : [], '시간의 모래' : [], '공간의 성배' : [], '이성의 왕관' : [], '부옵션' : []})
Relic_Information = pd.DataFrame({'캐릭터 이름' : [], '성유물' : [], '평가': []})
driver = webdriver.Chrome('chromedriver.exe')
# 엑셀 전체 인덱스를 의미
# 저장할 엑셀이 두 개이기 때문에 인덱스도 두 개가 필요
total_index = 0
relic_index = 0
# 특정 캐릭터의 상세정보에서 오류가 발생할 경우을 대비
try :
for k in range(len(Main_link)) :
driver.get(Main_link[k])
time.sleep(3)
# 캐릭터의 무기 수집 과정
attack = driver.find_elements(By.CLASS_NAME, 'cIflhYhI')
for i in range(len(attack)) :
if '무기' == attack[i].text :
attack_index = i+1
break
weapon = attack[attack_index].text
# 캐릭터의 성유물 수집 과정
info = driver.find_elements(By.CLASS_NAME, 'D7SMSdcV')
for i in range(len(info)) :
# 권장 성유물 옵션을 파악하기 위해 위치를 저장
if '권장 성유물' in info[i].text :
index = i
break
# 권성유물의 정보가 담긴 공간
sung = info[index]
# 권장 성유물 옵션 수집 과정
options = sung.find_elements(By.CLASS_NAME, 'cIflhYhI')
Option = [Character[k], weapon]
for j in range(len(options)) :
# 권장 성유물 옵션에서 필요한 정보가 들어있는 부분
if j in [4, 5, 6, 8] :
option = options[j].text
# 옵션이 여러 개일 경우, 줄바꿈으로 구분하기 때문에 이를 / 구분으로 변경
if '\n' in option :
option = option.replace('\n', ' / ')
Option.append(option)
# 권장 성유물의 옵션만 담는 부분
Information.loc[total_index] = Option
total_index = total_index+1
# 추천 성유물 세트 및 상세 설명 수집 과정
sets = sung.find_elements(By.CLASS_NAME, 'W078FM6Z')
# 성유물 세트는 캐릭터마다 여러 개 존재하기 때문에 이를 구분하기 위한 부분
character_number = 1
for j in range(len(sets)) :
# li로 구분되어 있는데, 그 안에 div가 같이 들어가 있기 때문에 문제가 발생한다.
relic_info = list(sets[j].text.split('\n'))
for m in range(len(relic_info)) :
# 실제 정보가 들어가 있는 부분
if m%2 == 1:
one_set = relic_info[m-1]
set_info =relic_info[m]
character_name = Character[k]+'%d' %(character_number)
Option = [character_name, one_set, set_info]
Relic_Information.loc[relic_index] = Option
character_number = character_number+1
relic_index = relic_index+1
except Exception as e :
print(e)
print(Main_link[k])
with pd.ExcelWriter('genshin.xlsx') as writer :
Information.to_excel(writer, sheet_name='성유물 옵션', index=False)
with pd.ExcelWriter('genshin_set_relic.xlsx') as writer :
Relic_Information.to_excel(writer, sheet_name='성유물', index=False)
- 두 번째 코드 결과물


- 세 번째 코드
import pandas as pd
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as E
from openpyxl import *
# 원신/성유물 나무위키 링크
link = 'https://namu.wiki/w/%EC%9B%90%EC%8B%A0/%EC%84%B1%EC%9C%A0%EB%AC%BC'
driver = webdriver.Chrome('chromedriver.exe')
driver.get(link)
time.sleep(3)
Relic = pd.DataFrame({'성유물 세트' : [], '2세트' : [], '4세트' : [], '획득처' : [], '비경' : []})
total_index = 0
# 성유물 세트 효과 수집 과정
info = driver.find_elements(By.CLASS_NAME, 'TiHaw-AK._6803dcde6a09ae387f9994555e73dfd7')
for i in range(len(info)) :
# 첫 번째 성유물이 검투사의 피날레이기 때문에 해당 부분이 기준
# 여기서부터 끝까지가 성유물에 대한 정보가 존재
if '검투사' in info[i].text :
index_start = i
break
# 전체적으로 3단위로 원하는 정보가 있음
for i in range(index_start, len(info), 3) :
relic_info = info[i].text.split('\n')
# 1세트 효과가 있는 4성 성유물은 생략한다.
if '모시는 자' in relic_info[0] :
continue
# 획득처에서 비경을 구분하는 과정
if '비경' in relic_info[7] :
place_index_start = relic_info[7].index(':')
place = relic_info[7][place_index_start+2:]
if ',' in place :
place_end_index = place.index(',')
place = place[:place_end_index]
else :
place = ''
relic = [relic_info[0], relic_info[3], relic_info[5], relic_info[7], place]
Relic.loc[total_index] = relic
total_index = total_index+1
with pd.ExcelWriter('genshin_relic.xlsx') as writer :
Relic.to_excel(writer, sheet_name='성유물', index=False)
- 세 번째 코드 결과물

해당 데이터를 활용하여 원신 캐릭터의 성유물을 엑셀에서 쉽게 조회하는 포스팅은 아래에서 확인해주세요!
[원신] 성유물 세팅 엑셀로 쉽게 보기 (4.5 업데이트 기준, 치오리 포함)
안녕하세요! 오늘은 원신 4.5 업데이트 모든 캐릭터 성유물 세팅 포스팅을 진행하겠습니다. 4.5 업데이트는 간단한 업데이트여서 호다닥 갖고 왔습니다. 캐릭터의 성유물 세팅은 엑셀 내 저장되
yhj9855.com
코드에 대해 궁금한 부분이 있으신 분들은 댓글로 남겨주시면, 답변 드리도록 하겠습니다!

★읽어주셔서 감사합니다★
'Python(파이썬) > Crawling(크롤링)' 카테고리의 다른 글
| [Crawling] 네이버 뉴스 크롤링 코드 변경 (40) | 2024.03.27 |
|---|---|
| [Crawling] 네이버 뉴스 크롤링 - 3 (72) | 2024.01.11 |
| [Crawling] 네이버 뉴스 크롤링 - 2 (74) | 2024.01.08 |
| [Crawling] 네이버 뉴스 크롤링 - 1 (57) | 2024.01.05 |